Numbers
- Compute nodes: 584
- CPU Cores: 14,016
- Performance:
- Theoretical max: 766.6 TFlop/s (entire system)
- Theoretical max: 560.6 TFlop/s (CPUs only)
- Linpack performance: 462.4 TFlop/s (CPUs only)
- Memory: 64.5 TB RAM
- Interconnect: InfiniBand FDR (56 Gbit/s)
- Operating system: Linux (Centos 7)
Nodes
To cover as many users’ requirements as possible our cluster is built on three kinds of nodes. All nodes have the same base configuration:
- Lenovo NeXtScale nx360 m5
- Two Intel E5-2680v3 CPUs each with 12 CPU cores and a theoretical performance of 480 GFlop/s.
- 64 GB RAM
- 200 GB local SSD local storage
- One high speed InfiniBand uplink connection for communication with the other nodes
448 Slim Nodes
As specified above in the base configuration. 256 of the slim nodes have 400 GB SSD.
64 Fat nodes
As the base configuration except that each node contains in total 512 GB RAM and 400 GB SSD
72 GPU nodes
As the base configuration except that each node contains 2 nVidia K40 GPU cards each with 2880 CUDA cores, and 12 GB RAM. The theoretical performance for each K40 is 1.43 TFlop/s.
Network
The compute nodes are connected using high-speed InfiniBand FDR (56 Gbit/s) equipment from Mellanox. To reduce cost while maintaining good inter-node speed, the InfiniBand switches are connected using a 3D torus (a 3x3x4 3D torus) as shown in the figure below.
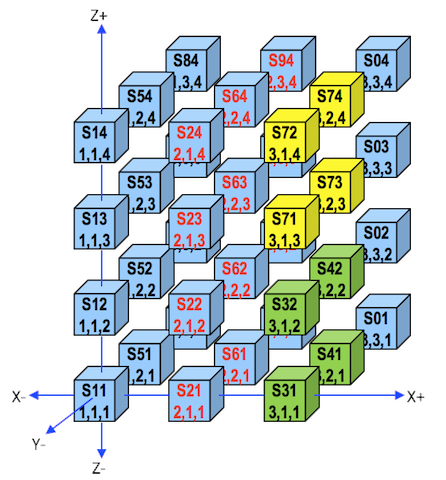
Each box in the figure, e.g., s51 (1,2,1), corresponds to an InfiniBand switch.
- The slim nodes are connected to the 28 “blue” switches (16 nodes/switch)
- The gpu nodes are connected to the 4 green switches (18 nodes/switch)
- The fat nodes are connected to the 4 yellow switches (16 nodes/switch).
Each switch is connected to its its 6 neighbour switches, e.g., s24 (2,1,4) is connected to:
- x-direction: s14 (1,1,4) and s72 (3,1,4)
- y-direction: s94 (2,3,4) and s64 (2,2,4)
- z-direction: s23 (2,1,3) and s21 (2,1,1)
The storage nodes are connected to all the switches in the s2x, s6x and s9x columns.
Scheduler
If possible, the job scheduler (Slurm) packs jobs such that the nodes used are as closely connected and are on as few switches as possible. If you use at most 16 nodes (slim and fat nodes) or 18 nodes (GPU nodes), it is possible to schedule the job such that all nodes are on the same switch. For more information, look at our Slurm.
Storage
All compute nodes have a local SSD disk which can be used for local storage during computations. On top of this users can use our network storage which is a Lenovo GSS26 system running GPFS.
Except for the local node storage, all user accessible nodes can access all file systems mentioned below.
Local node storage – $LOCALSCRATCH
- Can be used to store files and perform local I/O for the duration of a batch job.
- 330 GB (150 GB on gpu nodes) available on each compute node on a local disk
- It is some times more efficient to use and store files directly in $SCRATCH (to avoid moving files from $LOCALSCRATCH at the end of a batch job).
- Files stored in the $LOCALSCRATCH directory on each node are removedimmediately after the job terminates.
Home directory – $HOME
- This is your home directory. Store your own files, source code and build your executables here.
- At most 10 GB (150 k files) per user. Plus 10 GB for snapshots up to ten days back
- Note: if you change and delete many files in $HOME during the 10 days, the amount of snapshot space may not suffice, and you will only have snapshots fewer days back.
- Snapshots are taken daily.
Work directory – $WORK
- Store large files here. Change to this directory in your batch scripts and run jobs in this file system.
- Space and number of files in this file system is setup for each project based on each project’s requirements. Quota is shared among all users within a project.
- The file system is not backed up.
- Purge Policy: the $WORK filesystem is purged 3 months after the end of the project, i.e., all the information stored on this filesystem relative the specific project will be automatically deleted with no possibility of recovery.
Scratch directory – $SCRATCH
- Temporary storage of larger files needed at intermediate steps in a longer run. Change to this directory in your batch scripts and run jobs in this file system.
- This file system is not backed up.
- HPC staff may delete files from $SCRATCH, if the file system becomes full, even if files are less than 10 days old. A full file system inhibits use of the file system for everyone. The use of programs or scripts to actively circumvent the file purge policy will not be tolerated.
Files in the work and scratch directories are owned by the Project´s Principal Investigator (PI), who can revoke access from project members and change ownership of files. Files in home directories are owned by the individual user and can only be accessed by the user.